该大学入学考试的完整数学文章将重新考虑!对
- 编辑:admin -该大学入学考试的完整数学文章将重新考虑!对
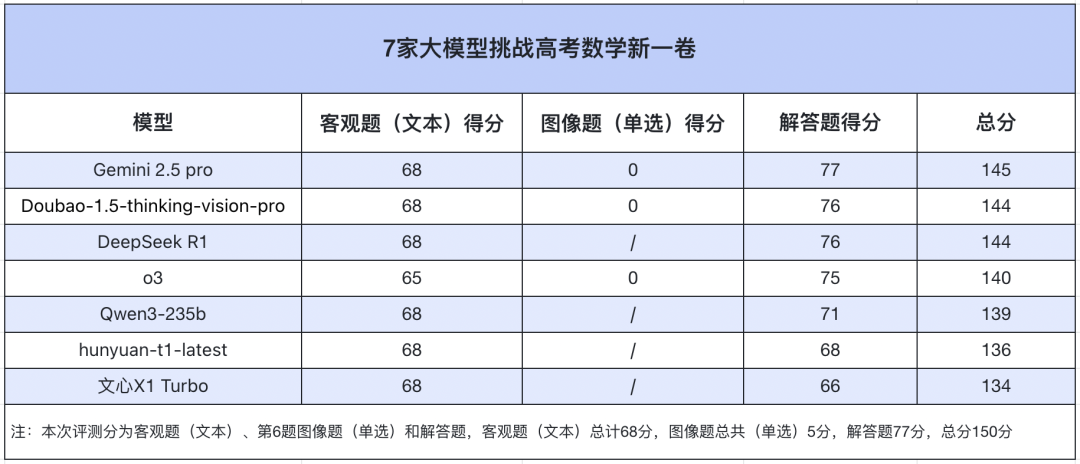 挑战AI在这里!继续在大学入学考试中进行数学问题的最后一集。大学入学考试的数学结束后,在夜间使用了六种大型模型产品,并在捕获普通用户的方法之后,询问了大学入学考试的最新客观问题。但是,一些互联网用户质疑评估过程不够严格,因此这次我添加了答案并再次尝试。参加这项任务的参赛者是Gemini 2.5 Pro,Doubao-1.5-Connsigio-Visco-Pro,DeepSeek R1,Qwen3-235b,Hunyuan-T1-Latest,Wenxin X1 Turbo,O3和Gemini 2.5 Pro非常激动。上次我使用Web侧面测试时,但是这次我排除了除O3以外的所有其他称为API的模型。关于考试问题,新的数学课程2025纸质标准I。5回答问题,总计77分。作为问题6包含照片S,加载问题的屏幕截图,以提取和评估多模式模型。所有其他文本问题成为乳胶格式,并单独馈送大型模型。那仍然是相同的规则。它不使用系统的指示方向,不启用网络搜索,也不会直接生成结果。 (注意:问题17还包括一张照片,但是文本也以乳胶格式进行了评估,因为很清楚,不影响问题的答案)。目标问题得分方法基于资格在大学入学考试之前的原则。唯一的选项问题是5分,如果获得了正确的选择,并且获得了错误的选项,则无需分。我问他们每个选项,获得6分,获得完整的匹配项6分,并且根据正确答案的数量获得丢失的选项。如果答案是ABCD,则选择为1.5分,如果未给出错误的选项,如果未给出错误的选择,则没有给出错误的选择,则未给出错误的选项。如果空白问题是5分,则正确的分数是正确的分数,并且未给出错误的答案,则未给出点。关于回应,主要的是分析对大型模型的最终响应,以及解决方案中存在严重错误。下图显示了七个大型模型测试的结果。从目标问题来看,每个大型模型很少会扩大差距,最大得分仅为3分。问题6中的图像中的问题甚至使这些大型多式模型“燃烧”。在挑战性的调查中,O3的客观问题在底部得分,但一些互联网用户说这是因为有原因使后端自动更改为其他模型。这次,我们选择了O3,它不会“减少智慧”,还有空间问题和多个选择n最终得分。当然,与“减少智慧”版本相比,65点得分实际上是一个重要的进步。回答问题是大型模型中失去点的“受到严重影响的领域”。除了获得所有分数的Gemini 2.5 Pro以外,其他模型丢失了或多或少的点。其中,DeepSeek R1和Doubao是最令人失望的,只有一个丢失。 O3输了两分,最终得分75分。相比之下,Ayuan-T1-Latest和Wenxin X1 Turbos分别赢得了68和66。在总得分方面,双子座2.5提出了145分,第一名和Doubao和DeepSeek R1紧密接近,获得144分。 O3和Qwen3仅在一个点上有所不同,分别排名第三和第四。由于答案中的“药物”,最后两个hunyuan-t1-latt和wenxin X1涡轮增压范围的总得分。 (请参阅每个主要模型以及响应和资格的分类屏幕截图为了答案。 https://jiqizhixin.feishu.cn/docx/pr0pdzyowou92qxijqcc2oe7n2g)在问题15和17中,一个证明了概率问题,另一个证明了三个维度几何知识。这七个伟大的型号具有完美的品牌。问题16是一系列完整的问题,完整得分为15分。在证明它已经完成的同时,计算过程已经完成并且结果正确,所有分数都可以获得。大型模型的一般性能是好的,只有QWEN3答案是正确的,但是最终答案Aghe责骂了一个额外的假设评级并减去了一个点。问题18:椭圆方程和几何形状使许多大型模型混淆了。只有Doubao,DeepSeek R1和Gemini2.5 Pro才能获得17分,而其他模型则具有自己的扣除点。 qwen3之前的所有答案都很好,过程非常完整,但是最终的问题| PQ |不需要步骤使最大值最多9,结果存在偏差,并推导了点。 O3意味着答案(3)不会简化答案,也不会失去积分。 Wen Xin X1正确计算问题2(2)的点P的路径,但并未证明极端值。最远的点是直接计算的,导致结果错误,并减去6点。 Hunyuan-T1-Latest在前两个问题中的答案是正确的。在完成问题3点P的路径之后,所有这个错误,连续失去了5分。最后,最后一个问题是Gemini 2.5 Pro是唯一的大型模型。 Doubao仅指出振荡项的幅度大于零,但是振荡项的阶段也可以逆转,因此最大值很小,测试过程不够严格,并且推导了一个点。 DeepSeek R1讨论了有关情况(3),这在他身上发生了两种不同的解决方案,但没有提供监测的解释对于第一种类型的解决方案,因此推导了一个点。问题o3(2)这个想法是正确的,但是由于开场间隔和关闭间隔的差异,声明“完全重叠”是不正确的,并且推导了1分。 Hunyuan-T1-Latest的想法是一个真正的问题(2),但是测试过程是模棱两可的,有两个推论点。如果没有进行相关试验(3),则将进行PHI的价值,并推断两次。点。 Wenxin X1和QWEN3也丢失了问题2和问题3中的点。问题2是用于模棱两可的证据,并且未指定问题3。此外,Wenxin X1的错误大于大小,从而扣除了另一点。客观问题:一个图像问题使几个多模型模型混淆了。目标问题模型的总体表现不错,而无需考虑图像识别问题(问题6)。 Doubao,Qwen3,Gemini 2.5 Pro,DeepSeek R1,Wenxin X1 Turbo和Hunyuan-T1-Latest,所有均达到68 PO的高分INT,仅选择o3来解决多个问题和丢失点。在其中,O3在计算问题9的过程中忽略了“正棱镜”的重要条件。在建立坐标系统时,我们使用(x₀,y₀,0)表示点C的坐标来表示点A和(c,0,0)的坐标,但是正常棱镜的基础表示正常的三角形是正常的三角形。 y₀:c =2x₀=2y₀/√3。这将导致对选项B的评论。接下来,让我们看一下这张照片中的问题。不幸的是,这次评估的伟大的多模式模型在此图像识别问题中的性能下降。尽管Hunyuan-T1-Latest不处于多模式状态,但我尝试了Hunyuan-T1-Vision,但我也丢失了这个问题。相反,Doubao和O3至少正确地识别了坐标的位置,而双子座误解了风速的方向,只要他没有正确地识别基本坐标。通常,结果该评估的s表明,大型模型在数学推断能力方面取得了长足的进步,但是仍然有很多改进的利润率。例如,许多模型在回答问题时会失去积分。这反映了需要通过复杂的推理,严格的讨论和几个计算来增强大型模型的必要性。此外,所有测量的多模式模型都在识别有关图像的识别6.Masu时都有问题。这也暴露了对图形文本的理解中AI的当前不便。最后,神经大学的入学考试已经完成。我们希望所有候选人都有完美的结果和辉煌的未来!
挑战AI在这里!继续在大学入学考试中进行数学问题的最后一集。大学入学考试的数学结束后,在夜间使用了六种大型模型产品,并在捕获普通用户的方法之后,询问了大学入学考试的最新客观问题。但是,一些互联网用户质疑评估过程不够严格,因此这次我添加了答案并再次尝试。参加这项任务的参赛者是Gemini 2.5 Pro,Doubao-1.5-Connsigio-Visco-Pro,DeepSeek R1,Qwen3-235b,Hunyuan-T1-Latest,Wenxin X1 Turbo,O3和Gemini 2.5 Pro非常激动。上次我使用Web侧面测试时,但是这次我排除了除O3以外的所有其他称为API的模型。关于考试问题,新的数学课程2025纸质标准I。5回答问题,总计77分。作为问题6包含照片S,加载问题的屏幕截图,以提取和评估多模式模型。所有其他文本问题成为乳胶格式,并单独馈送大型模型。那仍然是相同的规则。它不使用系统的指示方向,不启用网络搜索,也不会直接生成结果。 (注意:问题17还包括一张照片,但是文本也以乳胶格式进行了评估,因为很清楚,不影响问题的答案)。目标问题得分方法基于资格在大学入学考试之前的原则。唯一的选项问题是5分,如果获得了正确的选择,并且获得了错误的选项,则无需分。我问他们每个选项,获得6分,获得完整的匹配项6分,并且根据正确答案的数量获得丢失的选项。如果答案是ABCD,则选择为1.5分,如果未给出错误的选项,如果未给出错误的选择,则没有给出错误的选择,则未给出错误的选项。如果空白问题是5分,则正确的分数是正确的分数,并且未给出错误的答案,则未给出点。关于回应,主要的是分析对大型模型的最终响应,以及解决方案中存在严重错误。下图显示了七个大型模型测试的结果。从目标问题来看,每个大型模型很少会扩大差距,最大得分仅为3分。问题6中的图像中的问题甚至使这些大型多式模型“燃烧”。在挑战性的调查中,O3的客观问题在底部得分,但一些互联网用户说这是因为有原因使后端自动更改为其他模型。这次,我们选择了O3,它不会“减少智慧”,还有空间问题和多个选择n最终得分。当然,与“减少智慧”版本相比,65点得分实际上是一个重要的进步。回答问题是大型模型中失去点的“受到严重影响的领域”。除了获得所有分数的Gemini 2.5 Pro以外,其他模型丢失了或多或少的点。其中,DeepSeek R1和Doubao是最令人失望的,只有一个丢失。 O3输了两分,最终得分75分。相比之下,Ayuan-T1-Latest和Wenxin X1 Turbos分别赢得了68和66。在总得分方面,双子座2.5提出了145分,第一名和Doubao和DeepSeek R1紧密接近,获得144分。 O3和Qwen3仅在一个点上有所不同,分别排名第三和第四。由于答案中的“药物”,最后两个hunyuan-t1-latt和wenxin X1涡轮增压范围的总得分。 (请参阅每个主要模型以及响应和资格的分类屏幕截图为了答案。 https://jiqizhixin.feishu.cn/docx/pr0pdzyowou92qxijqcc2oe7n2g)在问题15和17中,一个证明了概率问题,另一个证明了三个维度几何知识。这七个伟大的型号具有完美的品牌。问题16是一系列完整的问题,完整得分为15分。在证明它已经完成的同时,计算过程已经完成并且结果正确,所有分数都可以获得。大型模型的一般性能是好的,只有QWEN3答案是正确的,但是最终答案Aghe责骂了一个额外的假设评级并减去了一个点。问题18:椭圆方程和几何形状使许多大型模型混淆了。只有Doubao,DeepSeek R1和Gemini2.5 Pro才能获得17分,而其他模型则具有自己的扣除点。 qwen3之前的所有答案都很好,过程非常完整,但是最终的问题| PQ |不需要步骤使最大值最多9,结果存在偏差,并推导了点。 O3意味着答案(3)不会简化答案,也不会失去积分。 Wen Xin X1正确计算问题2(2)的点P的路径,但并未证明极端值。最远的点是直接计算的,导致结果错误,并减去6点。 Hunyuan-T1-Latest在前两个问题中的答案是正确的。在完成问题3点P的路径之后,所有这个错误,连续失去了5分。最后,最后一个问题是Gemini 2.5 Pro是唯一的大型模型。 Doubao仅指出振荡项的幅度大于零,但是振荡项的阶段也可以逆转,因此最大值很小,测试过程不够严格,并且推导了一个点。 DeepSeek R1讨论了有关情况(3),这在他身上发生了两种不同的解决方案,但没有提供监测的解释对于第一种类型的解决方案,因此推导了一个点。问题o3(2)这个想法是正确的,但是由于开场间隔和关闭间隔的差异,声明“完全重叠”是不正确的,并且推导了1分。 Hunyuan-T1-Latest的想法是一个真正的问题(2),但是测试过程是模棱两可的,有两个推论点。如果没有进行相关试验(3),则将进行PHI的价值,并推断两次。点。 Wenxin X1和QWEN3也丢失了问题2和问题3中的点。问题2是用于模棱两可的证据,并且未指定问题3。此外,Wenxin X1的错误大于大小,从而扣除了另一点。客观问题:一个图像问题使几个多模型模型混淆了。目标问题模型的总体表现不错,而无需考虑图像识别问题(问题6)。 Doubao,Qwen3,Gemini 2.5 Pro,DeepSeek R1,Wenxin X1 Turbo和Hunyuan-T1-Latest,所有均达到68 PO的高分INT,仅选择o3来解决多个问题和丢失点。在其中,O3在计算问题9的过程中忽略了“正棱镜”的重要条件。在建立坐标系统时,我们使用(x₀,y₀,0)表示点C的坐标来表示点A和(c,0,0)的坐标,但是正常棱镜的基础表示正常的三角形是正常的三角形。 y₀:c =2x₀=2y₀/√3。这将导致对选项B的评论。接下来,让我们看一下这张照片中的问题。不幸的是,这次评估的伟大的多模式模型在此图像识别问题中的性能下降。尽管Hunyuan-T1-Latest不处于多模式状态,但我尝试了Hunyuan-T1-Vision,但我也丢失了这个问题。相反,Doubao和O3至少正确地识别了坐标的位置,而双子座误解了风速的方向,只要他没有正确地识别基本坐标。通常,结果该评估的s表明,大型模型在数学推断能力方面取得了长足的进步,但是仍然有很多改进的利润率。例如,许多模型在回答问题时会失去积分。这反映了需要通过复杂的推理,严格的讨论和几个计算来增强大型模型的必要性。此外,所有测量的多模式模型都在识别有关图像的识别6.Masu时都有问题。这也暴露了对图形文本的理解中AI的当前不便。最后,神经大学的入学考试已经完成。我们希望所有候选人都有完美的结果和辉煌的未来!


